While large language models (LLMs) have impressed with their ability to reason and generate fluent text, the next frontier lies in connecting language with perception—bringing AI into the physical world. Vision-Language Models (VLMs) are at the heart of this shift, combining visual understanding with language-based reasoning. These systems don’t just “see” the world—they interpret it and act on it in real time, at scale.
This capability is critical for industries like manufacturing, logistics, datacenter operations, and quality control, where situational awareness and adaptability are key. VLMs can monitor factory and warehouse floors, detect anomalies on the fly, and respond to changing conditions across complex supply chains—cutting costs, boosting resilience, and powering smarter automation. They’re equally essential in safety-critical contexts such as disaster response, infrastructure monitoring, and surveillance. Vision systems are evolving from narrow, task-specific tools into general-purpose interfaces—gateways for AI to engage with the real world.
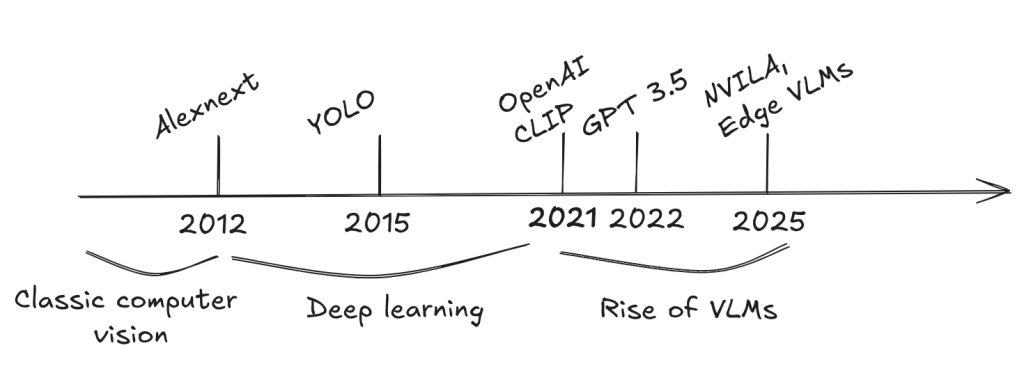
In this blog, we’ll trace that evolution: from hand-crafted pipelines to deep learning–driven perception, and now to today’s powerful multimodal architectures. These systems aren’t just technical milestones—they’re the foundation for AI’s deployment in the real world.
Vision systems prior to VLMs
From the 1970s to around 2012, computer vision was dominated by rule-based systems and handcrafted features. Vision tasks were typically framed as classification (e.g., identifying object categories) or regression (e.g., estimating numerical properties from images). Engineers manually designed features—like edge detectors, shape descriptors, and texture filters—often using brittle if-then rules and finely tuned thresholds. These systems assumed that expert-crafted features would be linearly separable, allowing for simple classifiers. But they were highly specialized, time-consuming to build, and poorly generalized beyond narrow use cases. Common tasks included edge detection, object classification, and segmentation—often developed with minimal data and significant engineering effort.
Everything changed in 2012 with the rise of deep neural networks. The deep learning era began with AlexNet, a convolutional neural network (CNN) that achieved a breakthrough in image recognition. With deep neural networks, especially convolutional neural networks and later vision transformers, vision systems began learning representations directly from raw pixel data. Instead of handcrafting features, engineers trained models end-to-end for various vision tasks.
The major task categories in deep learning–based vision include:
- Image Recognition: Neural networks classify images into predefined labels (e.g., defective vs. non-defective, stop sign vs. pedestrian). Prominent models include AlexNet, GoogLeNet, ResNet, and MobileNet.
- Object Detection: Networks like R-CNN, Fast R-CNN, and the YOLO family learn to localize and classify multiple objects by drawing bounding boxes around them—useful for detecting barcodes, mechanical parts, traffic signs, and more.
- Instance Segmentation: These models, such as Mask R-CNN, go further by generating pixel-level masks for each detected object, enabling fine-grained understanding of scenes.
Deep neural networks quickly proved more adaptable across diverse scenarios—provided they had access to large-scale labeled datasets, often with tens or hundreds of thousands of examples. A common architectural pattern emerged: a backbone network to learn general-purpose visual representations, followed by task-specific heads for classification or regression.
Transfer learning became a game-changer—models pre-trained on massive datasets could be fine-tuned for new tasks with relatively little data. This approach accelerated development, expanded the range of viable applications, and consistently delivered state-of-the-art results across vision tasks.
When properly trained, neural networks outperform classical methods in robustness to variations in viewpoint, lighting, color, and contrast—critical for deployment in real-world industrial environments.
Today, these models power the core of vertically integrated vision systems from companies like Cognex and Zebra. They run in high-performance cameras that detect barcodes, count packages on conveyors, and perform quality checks—often at hundreds of frames per second thanks to tightly optimized hardware-software stacks.
Despite their success and widespread adoption, deep learning–based vision systems fall short in one key area: reasoning. They can detect and classify objects, but they struggle to interpret state, configuration, or whether something complies with written instructions or standards. In essence, they “see,” but they don’t truly understand.
The Rise of VLMs
Vision-Language Models (VLMs) mark a fundamental shift in computer vision—from narrow, task-specific pattern recognition to general-purpose, multimodal reasoning.Unlike earlier deep learning models designed for single tasks like classification or detection, VLMs unify transformer-based vision and language models into systems that can understand and generate language grounded in visual context. This enables a broader range of capabilities: interpreting images and videos based on complex textual policies, identifying subtle or abstract concepts (e.g., specific types of damage, presence of foreign objects, or safety compliance violations), and making decisions with far greater contextual awareness.

VLMs use specialized backbones to convert both text and images into vector embeddings, which are then aligned and processed through adapters and token-generating heads. Trained on massive web-scale datasets using self-supervised learning, and often refined via supervised or reinforcement learning, these models learn to produce coherent, context-aware textual outputs grounded in visual input.Their architecture supports few-shot generalization through prompts, enabling them to handle a wide range of tasks—from comparisons and explanations to instruction following. This flexibility goes far beyond traditional classification: VLMs can reason, follow complex directives, and even power agents that act or use tools based on combined visual and linguistic context.
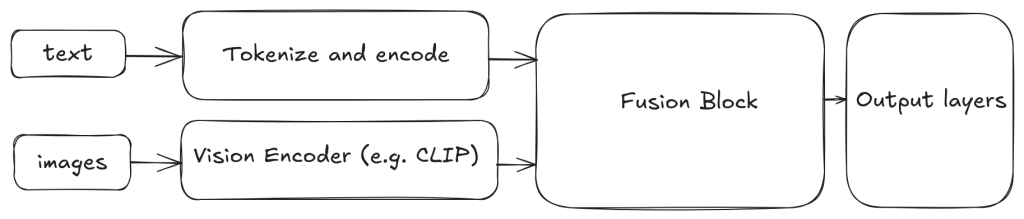
The first widely recognized vision-language model was CLIP (Contrastive Language-Image Pre-training), introduced by OpenAI in 2021. CLIP used large-scale image–text pairs to learn a joint embedding space, linking visual content with natural language. This approach—leveraging natural language supervision—enabled zero-shot image classification and other flexible multimodal tasks, marking a major breakthrough in vision-language modeling.
Since CLIP, more advanced models have pushed the boundaries of spatial and semantic reasoning. One notable example is LLaVA (Large Language and Vision Assistant), an open-source VLM released in April 2023. It combines image understanding with large language models (e.g., LLaMA) to support rich multimodal interaction.
Today’s leading vision-language foundation models include OpenAI’s GPT-4o, Anthropic’s Claude, and Google’s Gemini 1.5 Pro. These models are trained on massive web-scale image-text datasets and fine-tuned using proprietary methods. With hundreds of billions of parameters, they demand significant compute—often distributed across clusters of high-end GPUs—and are only accessible via cloud-based APIs.This reliance on the cloud presents challenges for industrial use. In many settings, high-bandwidth internet is unreliable or unavailable, and transmitting sensitive visual data to external servers raises security and compliance risks. Even when feasible, cloud inference often introduces latencies over five seconds—unacceptable for time-critical operations on factory floors or in logistics environments.
The Edge: the next frontier for VLMs
Beyond the large foundational VLMs, a new wave of smaller, edge-deployable models—such as VILA, Gemma 3, and Qwen2.5-VL — are enabling vision-language capabilities without relying on the cloud. One standout example is NVIDIA’s NVILA, introduced at CVPR this year. Built on the open-source LLaVA architecture, NVILA is fine-tuned on industrial and logistics datasets, making it well-suited for reasoning about real-world events in factories, warehouses, and other operational environments. NVILA achieves state-of-the-art performance on domain-specific industrial benchmarks. When properly quantized, smaller NVILA models can run directly at the far edge—for example, next to a camera monitoring an assembly line—without transmitting data to the cloud. Like other compact VLMs, NVILA can also be fine-tuned on specific datasets to further improve reliability. In our experience, even without fine-tuning, NVILA delivers roughly 85% of the performance of large cloud-based models like GPT-4o or Claude on industrial inspection tasks—while running fully on edge hardware.
More broadly, VLMs dominated this year’s CVPR: out of 2,878 accepted papers, nearly 300 focused on vision-language research. This reflects strong momentum in the academic and scientific community to improve VLM robustness, efficiency, and generalization across domains.
Just as deep learning replaced traditional vision pipelines in the mid-2010s, we expect VLMs to redefine industrial computer vision in the coming years—unlocking new levels of reasoning, context awareness, and autonomy far beyond the reach of previous systems.
In a follow on blog post, we will cover the development process using VLMs to solve real world problems, and value unlocked by Visum AI’s software.