Visum AI showcased a Vision Language Model (VLM) application in collaboration with Siemens Industry, Inc. at Automate 2025. The demonstration was developed jointly with Siemens and Nvidia. It received strong interest, with several prospective customers engaging in discussions about their own use cases and the potential of VLMs to drive meaningful business outcomes.


Automate 2025 is the largest robotics and automation event in the Americas, serving as a premier platform for showcasing cutting-edge technologies and innovations in the field. Additional information about Automate 2025 is available on LinkedIn and the official event website. Siemens Industry, Inc., a global leader in industrial automation and digitalization solutions, served as the lead sponsor for the event.
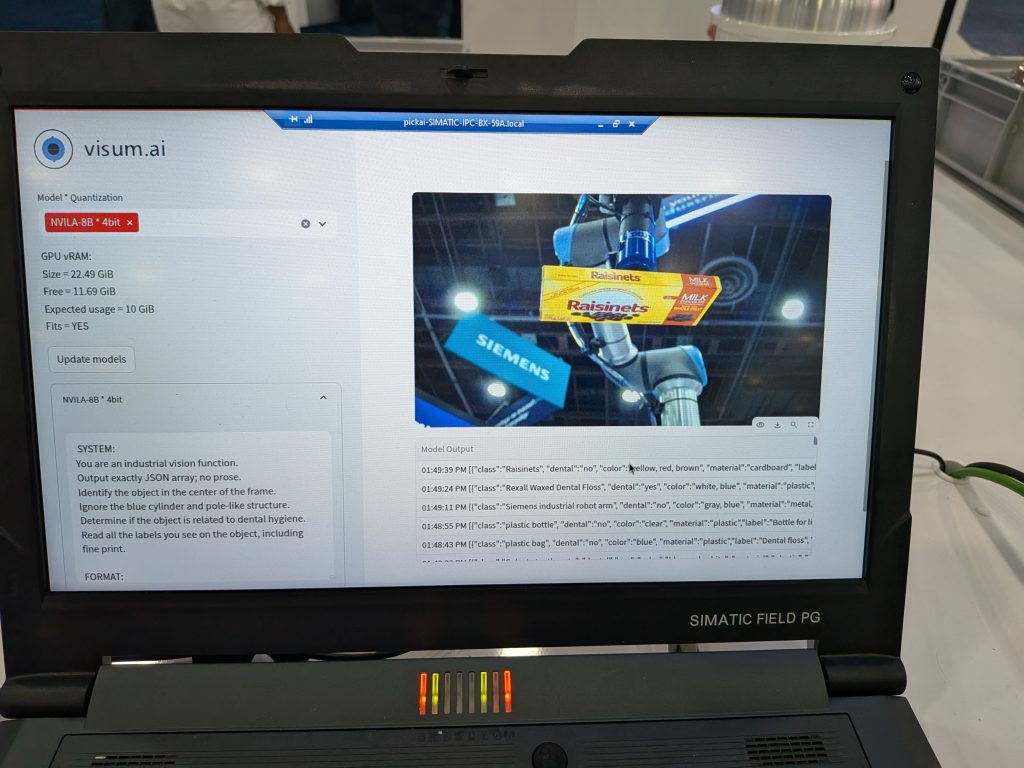
The demonstration highlights the capabilities of Vision Language Models (VLMs), offering the ability to select from a range of VILA and NVILA models originally developed by NVIDIA Research. These models are quantized to 4-bit and 8-bit precision and deployed on an edge device—a Siemens industrial PC equipped with an NVIDIA L4 GPU. The application supports loading multiple VLMs simultaneously, provided they fit within the available GPU memory. Once loaded, the models perform inference on images captured in real time from an integrated camera system.

For the purposes of this demonstration, an industrial-grade Basler camera was utilized. The application supports multiple image capture modes, including network trigger, Basler software trigger, and hardware trigger. In network trigger mode, images are captured either via a command sent through a network port or by using a capture button within the application interface. The Basler software stack facilitates the other two modes. In hardware trigger mode, image capture is initiated by an external hardware signal. In software trigger mode, the application was configured to capture images at regular intervals, with a frame acquired every 15 seconds.
The Siemens team developed a demonstration setup featuring a robotic arm that transferred objects from one bin to another. Objects were selected at random, resulting in a zero-shot object detection scenario. A hardware trigger was configured to activate the camera precisely when the robotic arm passed in front of it. Upon image capture, inference was sequentially performed using all loaded Vision Language Models. The output from each model was displayed on-screen and concurrently logged to a database, which could later be accessed through a secondary application for detailed analysis. The application allows one to specify a prompt for each VLM separately. With this setup, one can evaluate the efficacy of VLMs for a large variety of scenarios by modifying the prompts and capturing a variety of images.
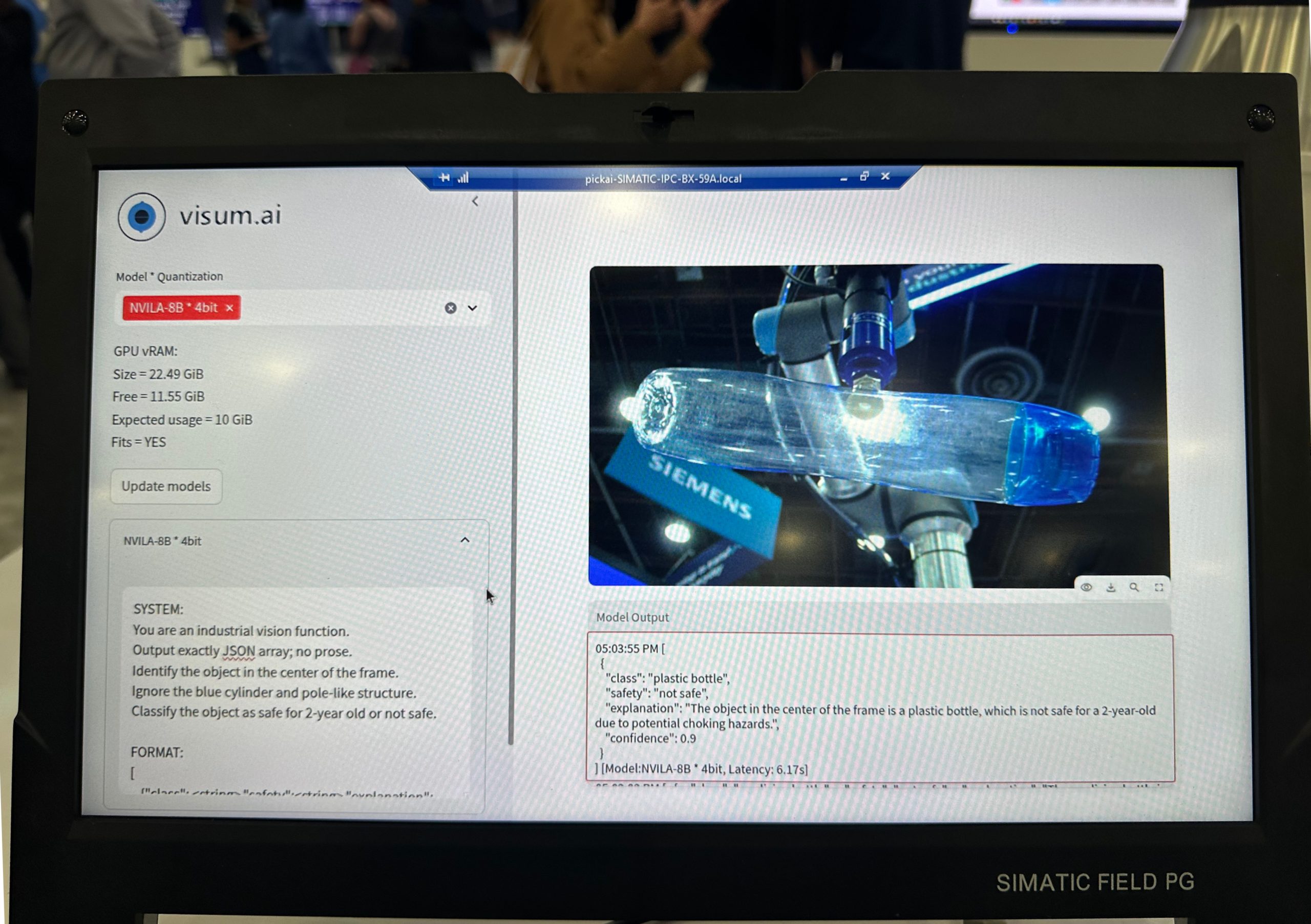

German Suorov, from Siemens, presented an overview of the demo, and highlighted the new capabilities of VLMs.
Please reach out to contact@visum.ai to schedule a private/customized demo for your use case.
Resources
- Visum AI’s flyer for Automate 2025.
Leave a Reply